roadmap
general
- Fix the items mentioned in issues.
- Architectural vision
- Optimize the system for the user, to be: accessible, in control, creative and fun.
- Work towards creating more data-defined software… do more with less code. This makes the software more 'malleable' and open-ended, for various contexts: datasources, fields (apps and websites), languages, custom functions (text-to-speech, bookmarking, etc.).
- Improve and maintain conceptual integrity of how the various Conzept framework pieces fit together: datasources, fields, URL structure, central configuration of common data across apps, easy intercommunication between apps, recursive Conzept views, 5D views (3D location + 1D time + 1D data-view).
- Get more engagement and feedback from users and software developers.
- What should and could be improved for them in the knowledge exploration and learning process?
AI
frontend AI
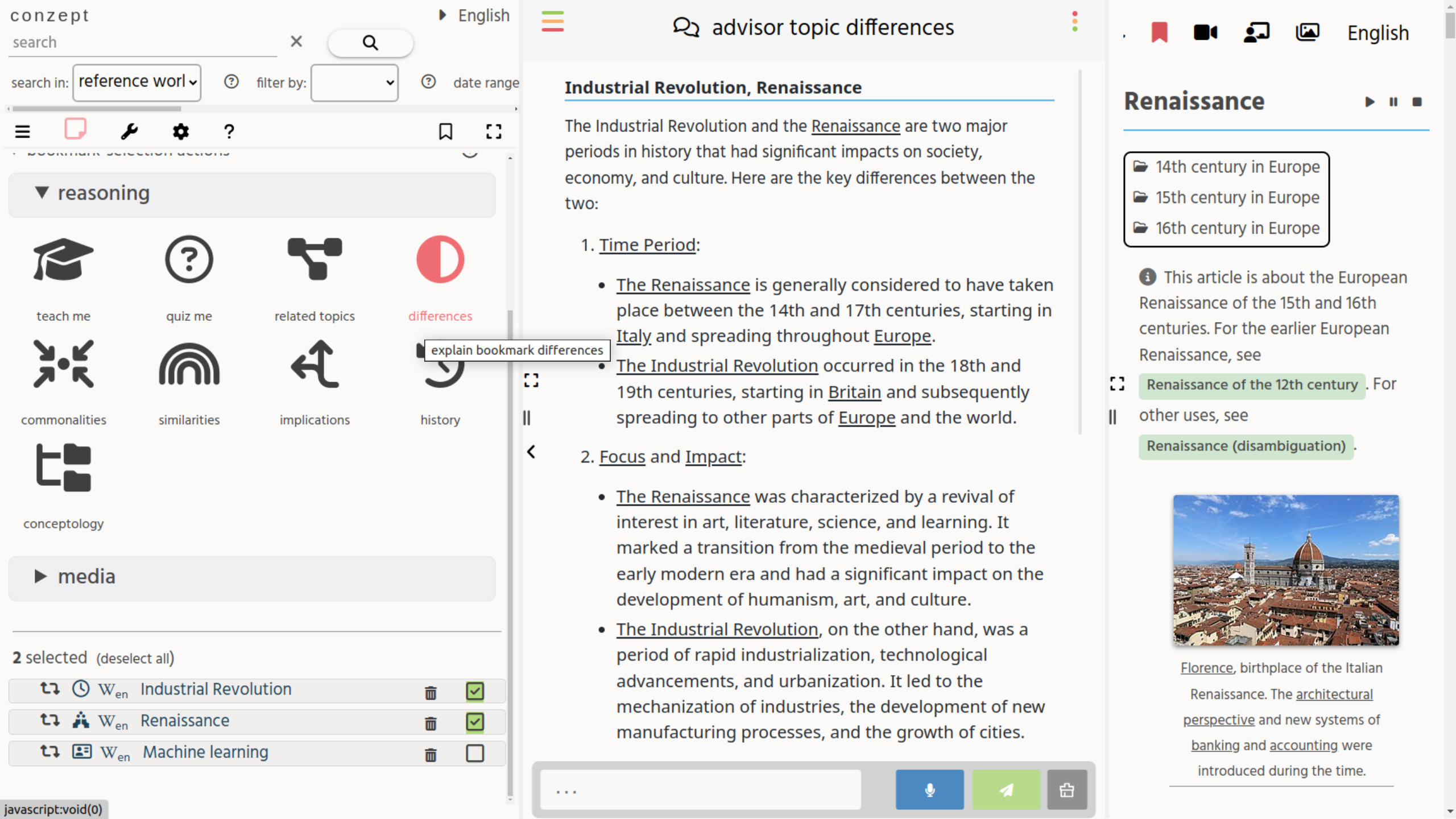
LLM reasoning over multiple topics (bookmark titles) (using OpenAI)
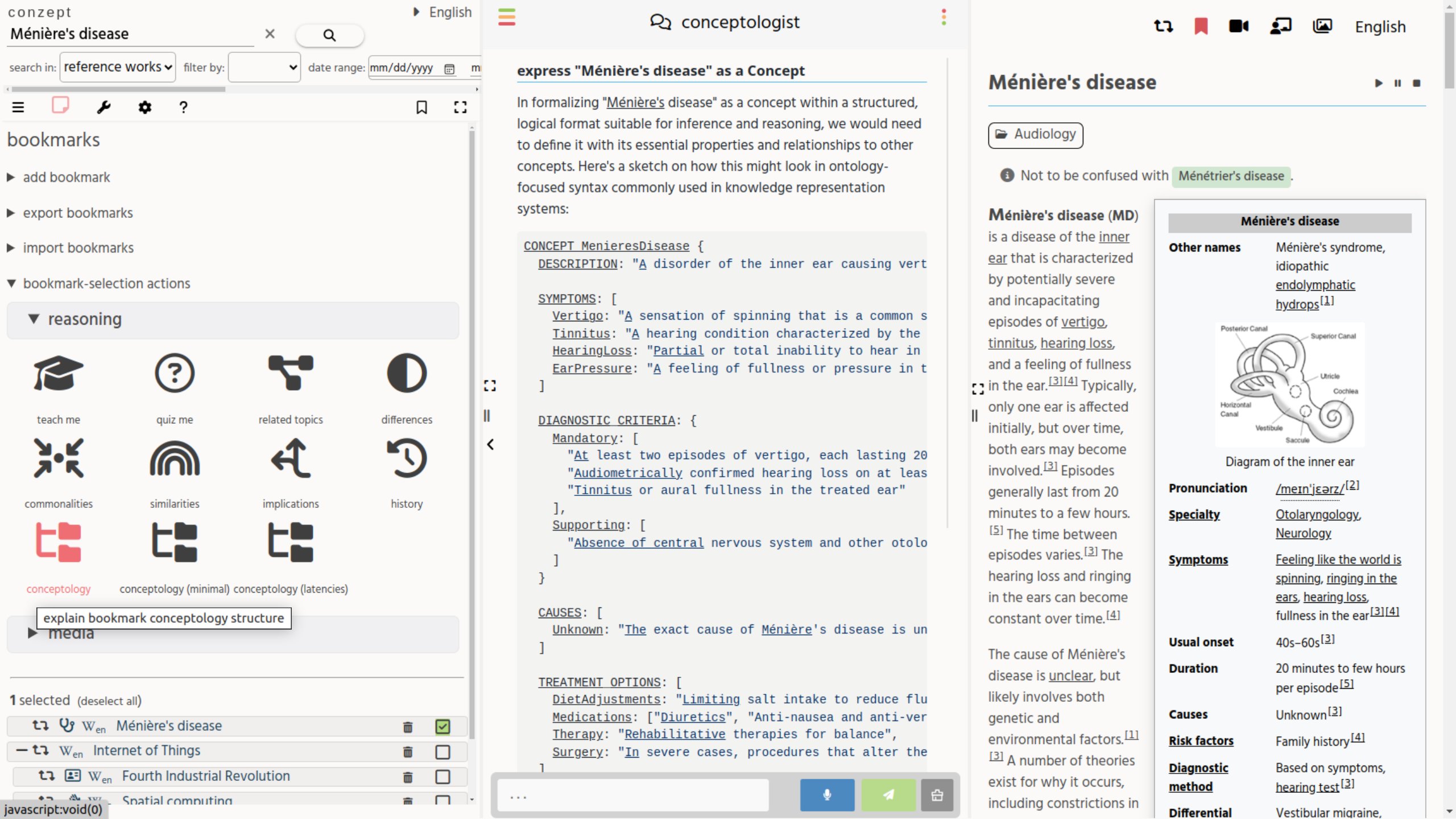
experiment with structured LLM output (using OpenAI)
- Main frontend AI goals:
- Topical question-answering
- Topical quizzing & examination
- Content summarization and Q&A of larger texts (including PDFs)
- Bookmark-selection reasoning (over one or more topics)
- See also: structured LLM output
- make this reasoning fully multi-lingual (currently only a few languages)
- Presentation augmentation (combined with TTS)
- Add AI-entries (text + TTS) in the presentation table-of-contents
Conzept's current vision for frontend LLM AI, is to enhance and combine the strengths of these two search contexts:
- Semantic search - Due to using clear graph “entities” (regardless of language), the semantic web context is often more rigid / safe / predictable / cheaper / faster / multi-lingual / correct / precise, than Vector-based searches.
- Keyword / phrase based Vector-search - this textual AI context is often more flexible, fluid and creative, than semantic-web style search context, but also requires a lot more compute.
If one starts with a more semantic grounding for LLM functions, by using semantic “entities” (such as identifying Wikidata Qids for a topic), each topic can have a clear context, upon which you can start prompting the AI for the preferred action/intention.
See the “structured LLM prompt” screenshot on the right, for an experiment of this. No text was typed by the user, the user only selected a bookmark, to be used with some AI-based reasoning function. This makes it possible to:
- Categorize the topics based on their bookmark meta-data. Based on the main and sub-tag and other special data-attributes.
- Combine multiple topics for a specific LLM-prompt. Eg. show a combined organism occurence map (for each topic with a GBIF ID).
- Make the LLM-prompting multi-lingual.
- web-llm-chat will be the main Conzept LLM AI app integration in the future.
- This integration is a work in progress (to replace the current, simple AI chat app)
- Current status: Self-hosting is working, TODOs:
- Get a laptop with support for WebGPU and enough VRAM to run good models.
- URL parameter context (issue)
- Most required features:
- Fully client-side
- WebGPU based (too slow otherwise)
- Multi-model (so both smaller/slower and larger/faster systems can be supported)
- Multi-modal (Not yet supported! Later other modalities, such as PDFs, audio and images should be usable.).
- Multi-lingual (partly supported, open issues: parameter support, …)
- Code:
- web-llm (core framework)
- Advantages of client-side AI models:
- Privacy
- Opensource
- Cheaper operation (after the initial hardware purchase)
- No 3rd-party AI-provider account needed
- No limits on AI-queries (both quantitative and qualitative)
- Flexibility and freedom how and where to use these AI models in the future.
- Furthermore the combination of: Retrieval Augmented Generation (RAG), a vector DB, and a LLM model, can also utilize the extra meta-data from a more grounded understanding of a topic .
- Candidate expiriment RAG tools:
- Ask-my-PDF (RAG + Vector DB + LLM QA)
- Mememo (RAG + Vector DB)
- Research how to integrate a (frontend) RAG-tool with Conzept
- INPUT: PDF URL + user language → RAG LLM UI
- What about “plain text” inputs?
- Related projects:
- Transformer.js (various)
- ask-my-pdf (pdf)
- pdf-chatbot (pdf)
- reor (notes)
- See also:
- Category theory with LLMs
- “The Bitter Lesson” (“The biggest lesson that can be read from 70 years of AI research is general methods that leverage computation are ultimately the most effective”)
backend AI
LLM/Vector/Hybrid AI powered, backend-search using Typesense. (see below)
search
backend search
Typesense logo

- Allow admins to create custom API-endpoints, for use as datasources (from JSON or CSV). (work in progress)
- Typesense (C++ based search-engine backend with LLM/Vector search support)
- Allow both for (quoted) keyword / phrase queries and vector-based queries (using a self-hosted LLM model).
- Conzept integration milestones:
- Experiment with Typesense data import and search.
- Design the Conzept data-workflow (data files, insert/update/index scripts), for multiple self-hosted datasources.
- Add the Typesense-server + setup steps to the Conzept Docker install.
- Create an IPTV datasource using the Typesense-server as an example.
- Open questions:
- Search-facets become possible for these Typesense-backed datasources (since we can view all results at once and extract the facets). Would it be a good idea to enable support for this when such a datasource is queried (and only that datasource)?
frontend search
- Enhance temporal-range input (date-min, date-max) with an optional, interactive date-range slider.
- Research feasability to allow datasource searches without a search-term, but with one or more search filters.
- Research if it would be possible to dynamically add datasource-specific filter-types (only when a single datasource is active!).
- This would allow for more fine-grained search type-filters, finetuned to a particular datasource.
- Eg. for library/book datasources: Author, Title, Publisher, Genre, Topic, Resource-location, ISBN/Some-ID, Availability, Legal-rights, …
- Consider adding multi-select for datasource sets.
- Consider adding a new global filter: “people” (which is quite common, and more specific than “entities”).
- Structured search using SPARQL (beyond Wikidata)
- Ontology classes
- Ontology properties
- Autocompletion
- Multi-lingual labels
- Handle CORS issues
- Improve existing search modalities:
- ? Wikidata: Allow for filtering by raw-text-strings in “structured search” (currently not supported in the Wikidata-query-builder)
- Wikidata: Add claim-support to the Wikidata-data fetching (and support for claim-data in the field-definitions).
- Speech-based search input
- How to allow for multi-line text input?
- How to combine speech-input with search commands?
-
- Currently this is used a little for AI-chat and simple mathematical graph plotting.
- How could we combine this with multi-modal, client-side AI?
- What other search-commands are needed?
- Improve existing datasources (use more datasource meta-data, better content views, remove “BETA” label, etc.)
- Implement async data-enriching in datasources (work in progress)
- This would eg. allow 3rd-party datasources with a Wikidata Qid (or some other related ID with metadata) in their results, to be enriched.
- Implement json-proxy support for HTTP header Authorization (using the key from settings.conf)
- To check: That the used header (on the frontend) is working for eg. “CourtListener”
- Independent active/autocomplete/search toggles per datasource. Eg. to allow for searching Wikipedia concepts in other datasources). More control over how datasources are used, with toggle-switches for:
- datasource is active (boolean toggle)
- datasource autocomplete (boolean toggle)
- datasource searching (boolean toggle)
presentation system
- Allow for presentation to be build from Conzept fields
- design reuirements: auto-positioning slides, handle the common start/end slides sets, …
- Allow for extra Text-to-Speech (TTS) storylines around a topic (beyond Wikipedia and Wikidata information).
- Related books, science articles (partly done), AI-generated summaries and other content, AI explain text selection, …?
- Allow for bookmarking presentations
browser extension
- Re-implement the Conzept extension with Manifest v3 support (MV3). This is a requirement for the Chrome extension store.
- Maybe look into using the Plasmo browser extension framework.
- Goal: Provide a right-click menu-option to search on Conzept (make it work in embedded iframes and perhaps PDFs too, if possible)
bookmarks
- Bookmarking:
- Cross-tab bookmark state-syncing
- Allow for bookmarking presentations
- Bookmark edit mode → then click on bookmark → display bookmark edit modal → save button
- Better generic data support, based on the “item data object”
- Add more input-formats:
- images (experimental support)
- drawings (using tldraw or excalidraw)
- speech-to-text transcript (webcomponent)
- audio (webcomponent)
- video (webcomponent)
- longer notes
- ? PDF
- Research better drag-and-drop support
admin-dev workflows
- Improve the workflow for adding datasources.
- There are some minor manual issues, when adding new datasources which can be automated/scripted away.
- The “datasources.js” function-calls can be cleanup in a few places.
- Field-translation support: Create a structure to store field-label translations (title and icon-title), both for Wikidata and non-Wikidata fields.
- Allow the json2fields script to fetch and store property translations too.
- Add a test-framework → start adding tests for the most essential / complex code parts
- How to detect if the field URL could be embedded (instead of opening a a new tab)? (run a headless browser loading an iframe with the URL, checking for CORS-errors?)
performance
- Add webworker-support and move (more and more) non-UI functionality to these workers.
- Research: What would be a good incremental approach (and framework) for adding this?
educational-support
- Collaborative & social learning features:
- shared audio and chat (eg. p2p audio-chat and text-chat rooms for each topic)
- Quizzing: Auto-generated, spaced-repetition-based facts learning (for a certain topic / set of topics / topic-domain)
- Experiencing / Simulating: eg. play Chess positions (done), …
- ? Note-taking integration (eg.: Bangle, …)
- Better ways to indicate personal and professional interests (similar to the persona-tags setting)
×
>
<
